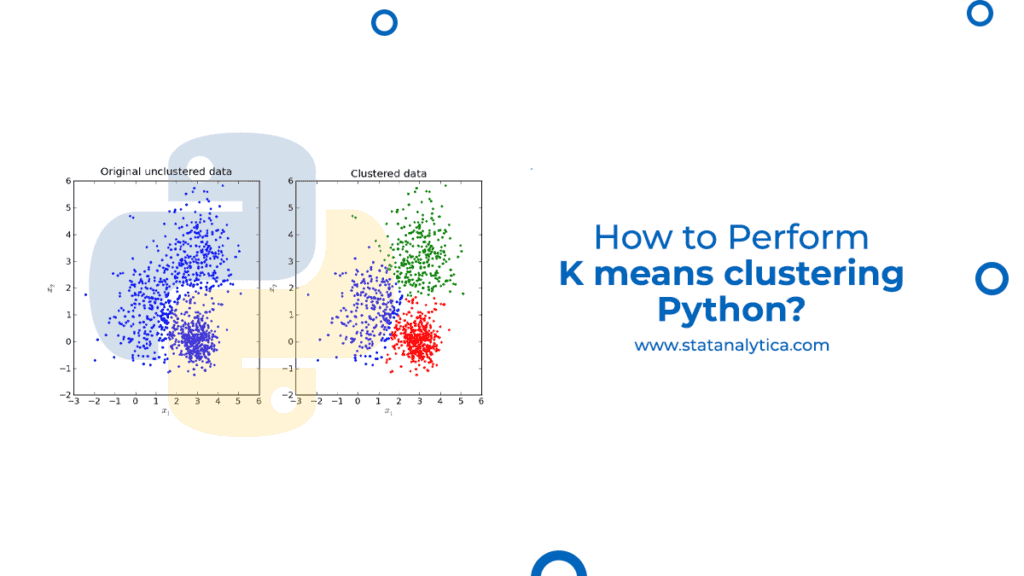
K Means Clustering Python
Salut ! Vous est-il déjà arrivé de ranger vos chaussettes par couleur ou de regrouper vos recettes préférées par type de plat (italien, mexicain, etc.) ? Eh bien, c'est un peu le même principe que le K-Means Clustering. Mais au lieu de chaussettes ou de recettes, on parle de données. Et au lieu de vos mains, c'est un algorithme Python qui s'en charge. On va décortiquer ça ensemble, promis, sans se prendre la tête !
Qu'est-ce que le K-Means Clustering, au juste ?
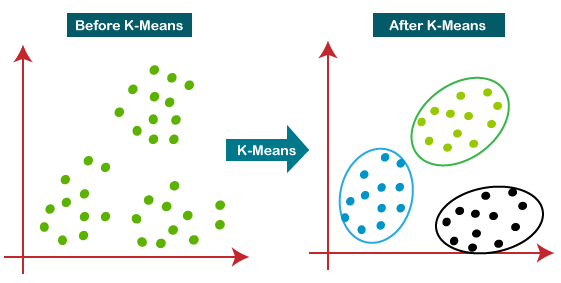
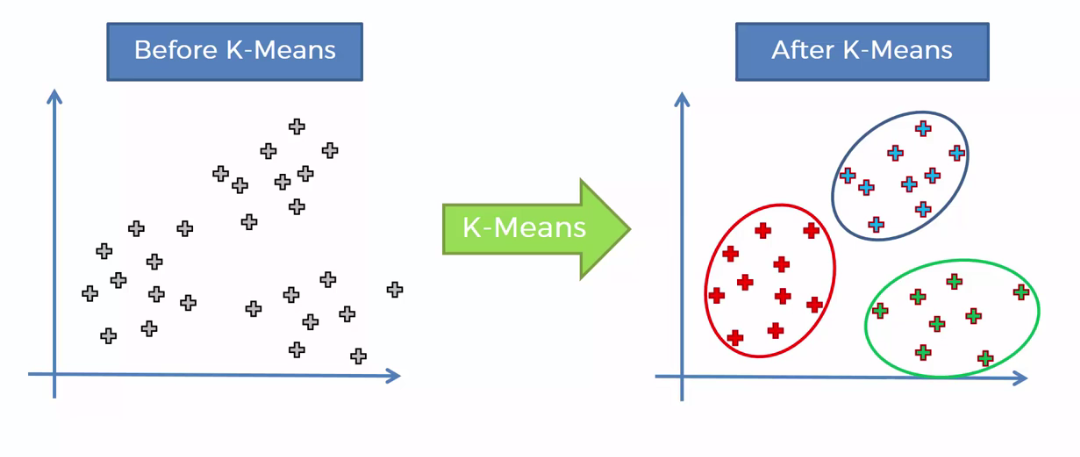
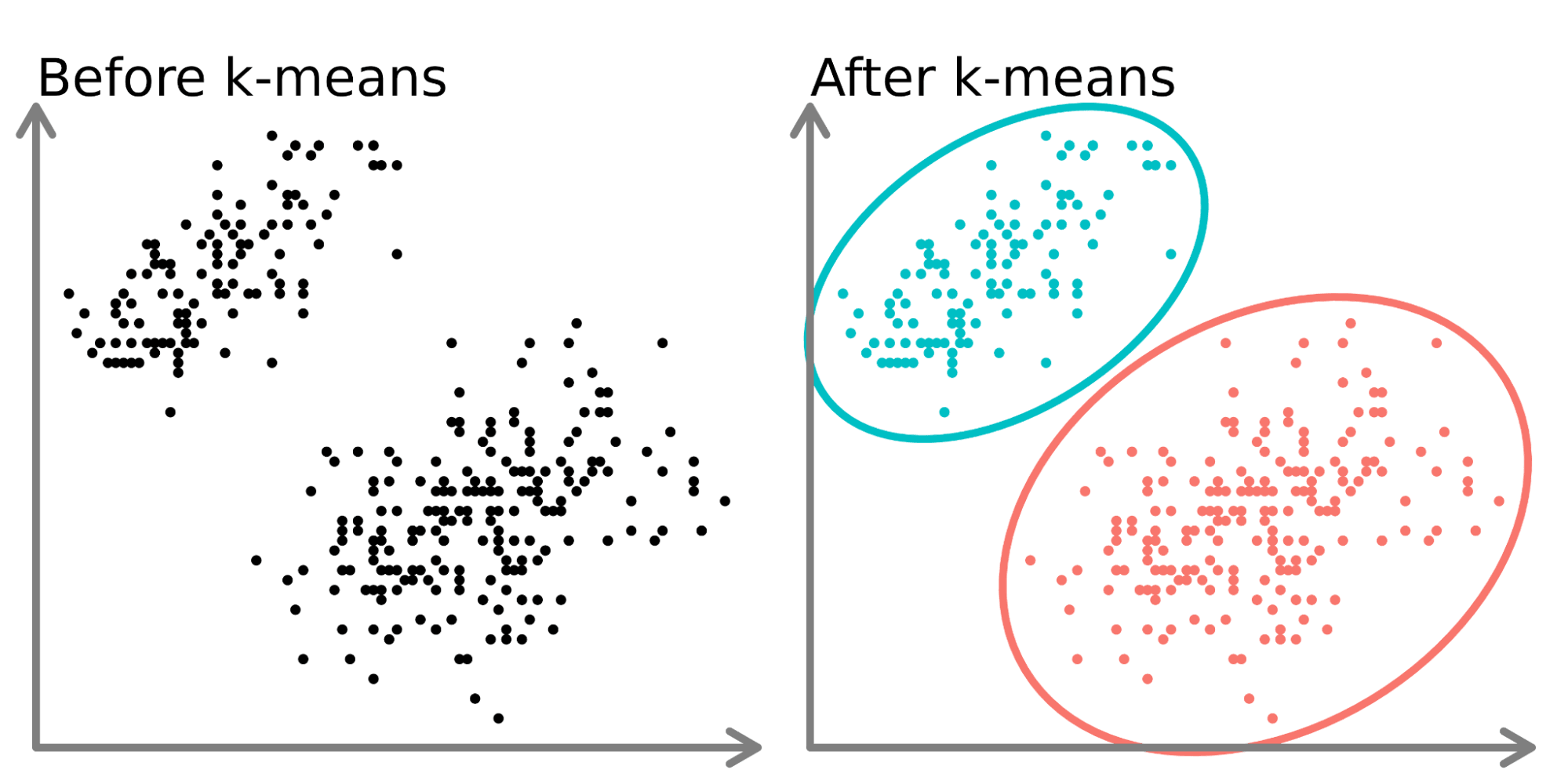
Imaginez que vous avez un immense sac de billes de toutes les couleurs. Le K-Means Clustering, c'est comme demander à un robot de les trier en groupes, en fonction de leur couleur. Sauf que, au lieu de couleurs, on parle de caractéristiques. Ces caractéristiques peuvent être n'importe quoi : l'âge, le revenu, la taille, le nombre de clics sur un site web, etc.
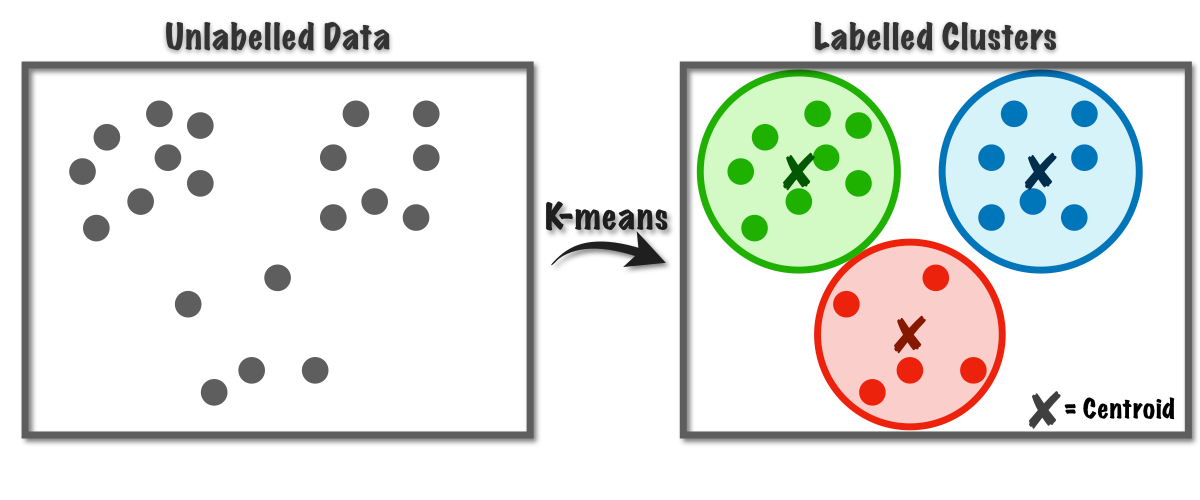
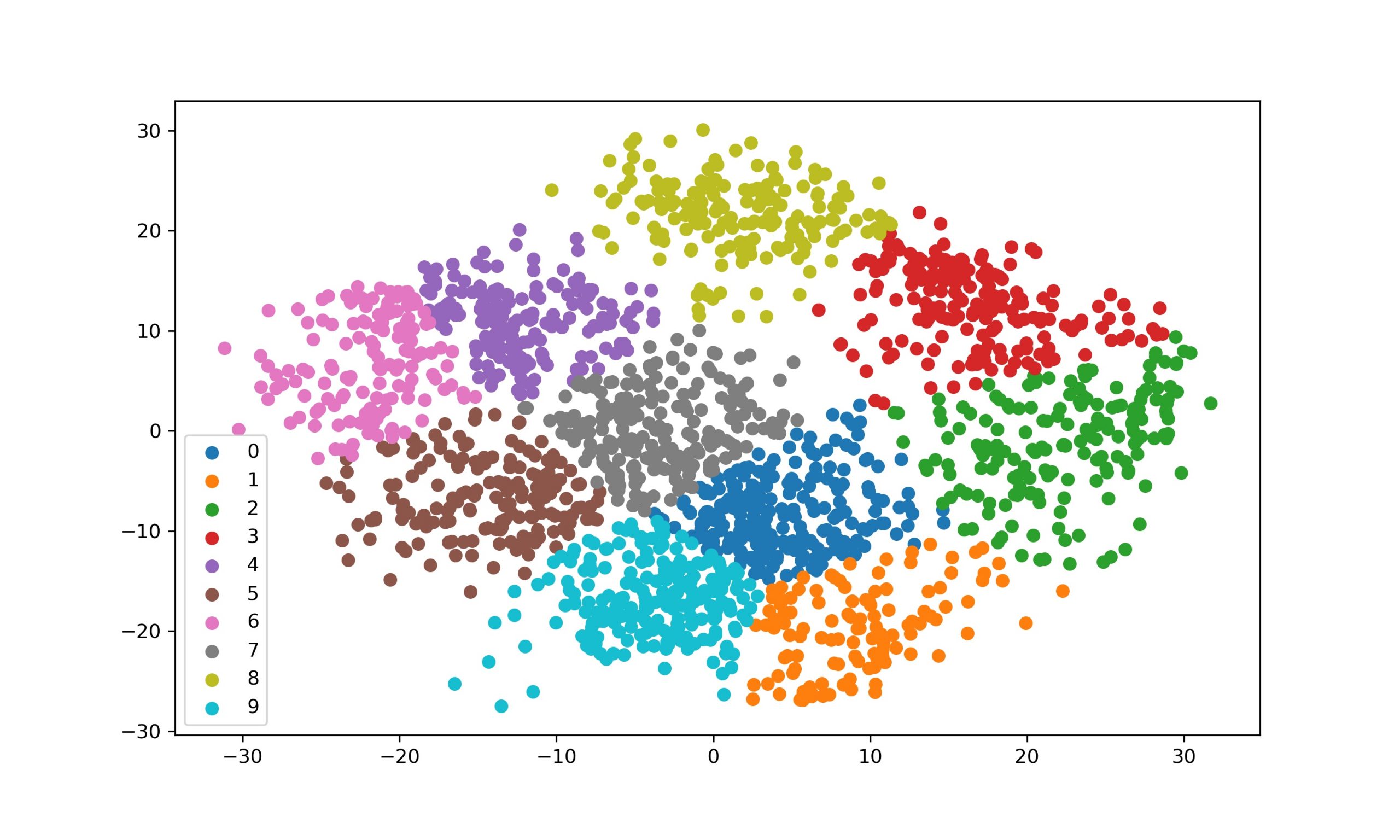
L'idée principale, c'est de regrouper les données les plus similaires entre elles. On définit un nombre de groupes, le "K", et l'algorithme se débrouille pour trouver les meilleurs centres pour chaque groupe. Chaque donnée est ensuite assignée au groupe dont le centre est le plus proche. C'est un peu comme créer des "quartiers" dans une ville en fonction des préférences des habitants.
Pourquoi "K-Means" ? "K" représente le nombre de clusters que vous voulez créer. "Means" fait référence à la moyenne (mean en anglais), car l'algorithme calcule la moyenne des points de données dans chaque cluster pour déterminer son centre. C'est tout simple en fait !
Pourquoi devriez-vous vous y intéresser ?
Alors, pourquoi apprendre tout ça ? Parce que le K-Means Clustering est partout ! Il est utilisé dans tellement de domaines différents que vous risquez d'être surpris.
Recommandations personnalisées : Vous vous demandez comment Netflix sait toujours vous proposer des films que vous allez adorer ? Eh bien, le K-Means peut être utilisé pour regrouper les utilisateurs ayant des goûts similaires. Si vous aimez les comédies romantiques avec Julia Roberts, l'algorithme va vous placer dans un groupe avec d'autres fans du genre et vous suggérer des films similaires.
Segmentation client : Les entreprises l'adorent ! Elles peuvent regrouper leurs clients en fonction de leur comportement d'achat, de leur âge, de leur localisation, etc. Cela leur permet de créer des campagnes marketing plus ciblées. Par exemple, si une entreprise de cosmétiques constate qu'un groupe de clientes achète principalement des produits anti-âge, elle peut leur proposer des offres spéciales sur ces produits.
Détection de fraudes : Les banques utilisent le K-Means pour repérer les transactions suspectes. En analysant les habitudes de dépenses des clients, l'algorithme peut identifier les transactions qui s'écartent de la norme et qui pourraient être frauduleuses.
Analyse d'images : On peut même l'utiliser pour segmenter des images ! Imaginez que vous ayez une photo d'un paysage. Le K-Means peut regrouper les pixels ayant des couleurs similaires, ce qui peut être utile pour identifier des objets ou des zones spécifiques.
En bref, le K-Means est un outil puissant pour trouver des modèles cachés dans vos données. C'est comme avoir une paire de lunettes spéciales qui vous permettent de voir les choses sous un angle différent !
Un peu de Python, sans paniquer !
Maintenant, passons à la partie pratique. Ne vous inquiétez pas, on va faire ça gentiment. Voici un exemple simple de code Python qui utilise la librairie scikit-learn (sklearn) pour effectuer un K-Means Clustering.
Installation des librairies :
Avant de commencer, assurez-vous d'avoir installé les librairies nécessaires. Vous pouvez le faire avec pip :
pip install scikit-learn matplotlib
Le code :
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
# 1. On crée des données (fictives, pour l'exemple)
X = np.array([[1, 2], [1.5, 1.8], [5, 8], [8, 8], [1, 0.6], [9, 11]])
# 2. On crée l'objet KMeans
kmeans = KMeans(n_clusters=2, random_state=0, n_init=10) # On veut 2 groupes
# 3. On entraîne le modèle (il trouve les centres des clusters)
kmeans.fit(X)
# 4. On affiche les centres des clusters
print("Centres des clusters :", kmeans.cluster_centers_)
# 5. On prédit le cluster auquel appartient chaque point
labels = kmeans.predict(X)
print("Labels des points :", labels)
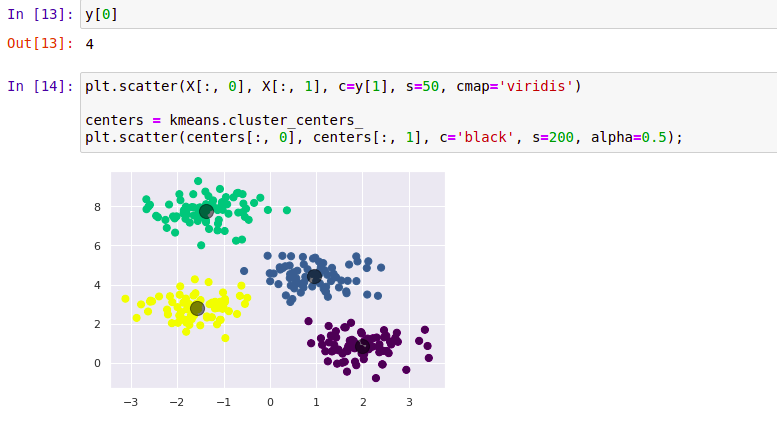
# 6. Visualisation (facultatif, mais sympa !)
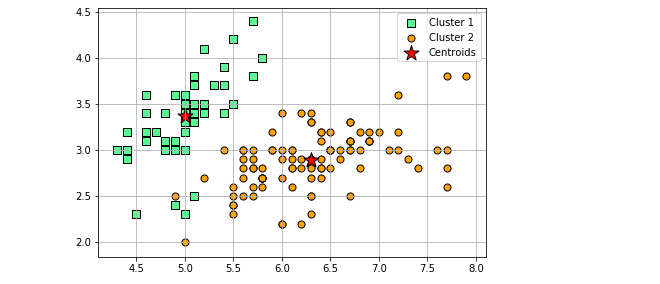
plt.scatter(X[:,0], X[:,1], c=labels) # On colore les points en fonction de leur cluster
plt.scatter(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,1], marker="x", s=200, linewidths=3, color='r') # On affiche les centres
plt.show()
Explication du code :
- Importation des librairies: On importe KMeans de sklearn.cluster, matplotlib.pyplot pour l'affichage, et numpy pour manipuler les tableaux.
- Création des données: On crée un tableau numpy appelé X qui contient nos données. Dans cet exemple, chaque point a deux coordonnées (x, y).
- Création de l'objet KMeans: On crée un objet KMeans et on précise qu'on veut 2 clusters (n_clusters=2). random_state est utilisé pour la reproductibilité et n_init détermine le nombre de fois que l'algorithme est exécuté avec différents centroïdes initiaux.
- Entraînement du modèle: La méthode fit(X) entraîne le modèle. Il trouve les centres des clusters qui minimisent la distance entre les points et leur centre respectif.
- Affichage des centres des clusters: On affiche les coordonnées des centres des clusters.
- Prédiction des labels: La méthode predict(X) prédit le cluster auquel appartient chaque point.
- Visualisation: On utilise matplotlib pour afficher les points et les centres des clusters. Les points sont colorés en fonction de leur cluster et les centres sont marqués d'une croix rouge.
Vous voyez, ce n'est pas si sorcier ! Bien sûr, c'est un exemple très simple, mais il vous donne une idée de la manière dont on utilise le K-Means en Python.
Quelques astuces et pièges à éviter
Le K-Means, c'est génial, mais il y a quelques petites choses à savoir pour l'utiliser correctement :
Choisir le bon nombre de clusters (K) : C'est souvent le casse-tête ! Il n'y a pas de formule magique. On utilise souvent des techniques comme la méthode du coude (elbow method) ou le coefficient de silhouette pour estimer le nombre optimal de clusters.
Sensibilité aux données initiales : L'algorithme peut donner des résultats différents en fonction de la manière dont les centres des clusters sont initialisés. C'est pourquoi il est important de l'exécuter plusieurs fois avec différentes initialisations (c'est ce que fait le paramètre n_init dans scikit-learn).
Données à la même échelle : Le K-Means est sensible à l'échelle des données. Si une caractéristique a des valeurs beaucoup plus grandes que les autres, elle aura une influence disproportionnée sur le résultat. Il est donc important de normaliser ou standardiser vos données avant d'appliquer l'algorithme. C'est un peu comme s'assurer que tout le monde parle la même langue !
Formes des clusters : Le K-Means a tendance à créer des clusters de forme sphérique. Si vos données forment des clusters de formes plus complexes, il risque de ne pas donner de bons résultats. Dans ce cas, il existe d'autres algorithmes de clustering plus adaptés, comme le DBSCAN.
Pour aller plus loin
Si vous êtes curieux d'en savoir plus, voici quelques pistes :
Scikit-learn : La documentation de scikit-learn est une mine d'informations. Vous y trouverez des exemples, des explications détaillées et des conseils d'utilisation.
Tutoriels en ligne : Il existe des tonnes de tutoriels sur le K-Means en Python. Cherchez sur YouTube, Medium ou d'autres plateformes d'apprentissage en ligne.
Projets pratiques : La meilleure façon d'apprendre, c'est de pratiquer ! Essayez d'appliquer le K-Means à des jeux de données réels. Vous pouvez trouver des jeux de données gratuits sur Kaggle ou d'autres sites web.
Voilà, vous avez maintenant une bonne base pour comprendre le K-Means Clustering. J'espère que cet article vous a plu et vous a donné envie d'explorer ce domaine passionnant ! N'hésitez pas à expérimenter, à poser des questions et surtout, à vous amuser ! C'est le meilleur moyen d'apprendre.
Alors, prêt à trier le monde avec le K-Means ? 😉



.png)